XTRAN Example — Vertically Align DSV Data
Scenario — you've inherited some code containing massive data initialization tables, and they're a mess. You want to clean them up so they're readable, but it's a huge editing job, because:
- The spacing of the DSV items is higgledy-piggledy, making it very hard to see what's what. You want to align each item based on its longest value, with extra spacing added for readability.
- The lines have different numbers of initialization values.
- For some of the DSV items, their values are all numeric, so you want them right-justified; all other item values should be left-justified.
- The code in question was originally C, so it
has
/*…*/comments. You are now treating it as C++, and you'd like to reformat those comments to C++'s//…form.
XTRAN to the rescue!
The following example uses an XTRAN rules file comprising 177 non-comment lines of "meta-code" (XTRAN's rules language) to vertically align DSV items, with many options. The rules took 2¾ hours to write and 1¾ hours to debug. (That's right, only 4½ hours total!)
The rules support the following options, which you can specify via environment variables:
- The DSV delimiting character, defaulting to comma.
- A regular expression (regexp for short) to match at the start of each line; if it matches, what matched is removed from the line, thereby exposing the start of the DSV items to be aligned.
- Text to prefix to each line on output. This could, for instance, be text removed by a regexp match at line start, as described above, or a replacement for it.
- Similarly, a regexp to match at the end of each line; if it matches, what matched is removed from the line, leaving only the DSV items to be aligned.
- Text to suffix to each line on output. This could, for instance, be text removed by a regexp match at line end, as described above, or a replacement for it.
- How many spaces (if any) to add for each item as padding.
- A multiple for item padding. If given, the rules will pad each item so its length is a multiple of this number. This can be useful, for instance, if you plan to tabify the results with hardware TABs after the alignment.
- A regexp to match a comment anywhere on each line. The regexp must contain exactly one group. If it matches, what matched the group is preserved as the line's comment, and what matched the regexp is removed from the line.
- A
printf()format to use when adding each line's comment (if any) as each line is output. - A column to which comments will be aligned on output.
To make it easier to specify regexps, the rules replace all underscores in them with spaces before using them.
In the example below, we extracted the relevant lines from
some code (highlighted in red) and used
these rules to clean them up, using the following options:
- Line start regexp:
____{ - Line prefix to add:
____{ - Line end regexp:
}, - Line suffix to add:
}, - Item padding:
1 - Comment regexp:
_*/\*\(.*\)\*/$ - Comment output format:
//%s - Comment column:
55
We then used the treated lines to replace the messy table initializations in the code.
We have, in fact, used these rules here at XTRAN, LLC to clean up some very large data initialization tables in XTRAN's own code. "Physician, heal thyself?" XTRAN did!
How can such powerful and generalized text formating be automated in only 4½ hours and 177 lines of XTRAN rules? Because there is so much capability already available as part of XTRAN's rules language. These rules take advantage of the following functionality:
- Text file input and output
- Text manipulation
- Text formatting
- Delimited list manipulation
- Regular expression matching
- Environment variable manipulation
- Content-addressable data bases
The input to and output from XTRAN are untouched, except for highlighting of treated code.
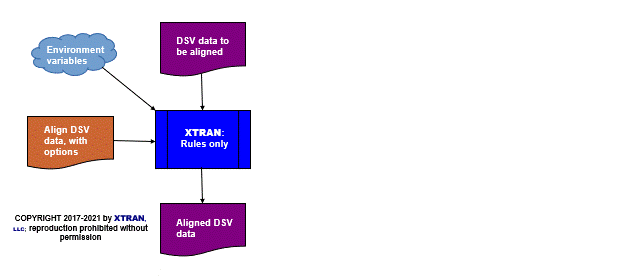
Process Flowchart
Here is a flowchart for this process, in which the elements are color coded:
- BLUE for XTRAN versions (runnable programs)
- ORANGE for XTRAN rules (text files)
- PURPLE for text data files
Input to XTRAN:
int arr[100][4] =
{
{ITEM1, ITM2,3,I4}, /*first line*/
{I5,Item6, 77, ITEM8},
…
{ITM9, 10, 11}, /*no 4th value*/
{IT12,I13,014,ITEM015},
{ 0 }
};
Output from XTRAN:
int arr[100][4] =
{
{ ITEM1, ITM2, 3, I4 }, //first line
{ I5, Item6, 77, ITEM8 },
…
{ ITM9, 10, 11 }, //no 4th value
{ IT12, I13, 014, ITEM015 },
{ 0 }
};
Note that, because all values of the 3rd item are numeric, the rules automatically right-justified that item, left-justifying everything else.