XTRAN Example — Combine C,
C++, Java, or C#
Expression Statements
Scenario — you have used XTRAN to translate assembly code to C, and the resulting translated code is rife with low-level statement sequences, reflecting the nature of the original assembly code.
XTRAN itself to the rescue!
The following example uses a set of XTRAN rules ("meta-code"), comprising 92 code lines, for re-engineering C, C++, Java, or C# by searching for situations in the code where expression statements can be combined to build more complex expressions.
The rules use XTRAN's powerful statement and expression pattern matching and replacement capabilities to automate the re-engineering. It uses two statement patterns, a match pattern and a replace pattern. The rules iterate through the code until no more replacements can be done. This has the effect that the result of a replacement is then examined for a possible subsequent replacement involving additional statements.
In the patterns below, this indicates C, C++, Java, or C#
elements and
<this> indicates meta
elements.
The match pattern is a two-statement pattern:
<expr1> = <expr2>;
<expr1> <asnopr> <expr3>;
where <exprn> match any
legal expressions and <asnopr>
matches an assignment operator such as /=
or +=. Note
that <expr1> must be the same in
both statements in order for the pattern to match.
The replace pattern is a single statement:
<expr1> = <expr2> <opr> <expr3>;
where <exprn> are
whatever expressions matched the
corresponding <exprn> in
the match pattern, and
<opr> is the
non-assignment version of whatever operator
matched <asnopr> —
* for *=, etc.
The effect of this pattern match and replacement is to combine consecutive expression statements, where it is possible to do so, by creating more complex expressions. For example, the rules would combine
str.arr[2] = a + b;
str.arr[2] *= c / d;
str.arr[2] -= e % f;
to
str.arr[2] = (a + b) * (c / d);
str.arr[2] -= e % f;
and then to
str.arr[2] = (a + b) * (c / d) - e % f;
Note, in the actual example below, that the rules also preserve all comments on all involved statements.
How can such powerful and generalized code transformation be automated in only 97 lines of XTRAN rules? Because there is so much capability already available as part of XTRAN's rules language. These rules take advantage of the following functionality:
- Text manipulation
- Text formatting
- Delimited list manipulation
- Statement and expression pattern matching and replacement
- Access to XTRAN's Internal Representation (XIR)
- Navigation in XIR
- Creating new meta-functions written in meta-code, which we call user meta-functions
- Delayed / forced rules evaluation
- Meta-variable and meta-function pointers
NOTE that the rendered code shown as XTRAN's output below was done with default conditions; XTRAN provides many options for controlling the way it renders code for output.
The input to and output from XTRAN are untouched.
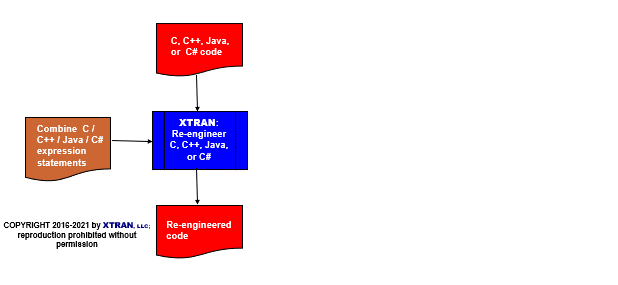
Process Flowchart
Here is a flowchart for this process, in which the elements are color coded:
- BLUE for XTRAN versions (runnable programs)
- ORANGE for XTRAN rules (text files)
- RED for
code
Input to XTRAN:
void prc(void)
{
short s1, s2, s3, s4;
s1 = s2; /*s1 = s2;*/
s1 += s3; /*s1 += s3;*/
s1 *= s4; /*s1 *= s4;*/
/*
* This is a comment preceding a series of s2 assignments.
*/
s2 = s1; /*s2 = s1;*/
s2 |= s4; /*s2 |= s4;*/
/*
* This is a comment in the middle of the s2 assignments.
*/
s2 &= s3; /*s2 &= s3;*/
s2 ^= s1; /*s2 ^= s1;*/
return;
}
Output from XTRAN:
void prc(void)
{
short s1, s2, s3, s4;
s1 = (s2 + s3) * s4; /*s1 = s2;*/
/*s1 += s3;*/
/*s1 *= s4;*/
/*
* This is a comment preceding a series of s2 assignments.
*/
/*
* This is a comment in the middle of the s2 assignments.
*/
s2 = (s1 | s4) & s3 ^ s1; /*s2 = s1;*/
/*s2 |= s4;*/
/*s2 &= s3;*/
/*s2 ^= s1;*/
return;
}