XTRAN Example — Load DSV Data into XTRAN Data Base
Menu
Introduction
Scenario — you're using XTRAN to automate data analysis and transformation, and you have a mass of delimiter-separated-values (DSV) data that you want to load into an XTRAN in-memory content-addressable data base (associative array), where you can manipulate it more easily.
XTRAN itself to the rescue!The following examples use an XTRAN rules file comprising 272 non-comment lines of XTRAN's rules language ("meta-code") to automate loading of DSV data into an XTRAN data base. The rules took 1¼ hours to create and 2 hours to debug. (That's right, only 3¼ hours total!)
The rules create a user meta-function you can call from your XTRAN rules to load DSV data into an XTRAN data base.
The meta-function assumes that a DSV data file's first non-comment line is a label row (a common practice with DSV files), and it uses those item labels as subscripts when it stores the data in the XTRAN data base.
In the meta-function call, you can specify (or default) the following:
- The name of the XTRAN data base into which the DSV data is to be loaded.
- The file specification of the DSV data file to be loaded. In that file specification, embedded environment variable names will be replaced by their values.
- (Optional) Whether or not to create the data base, defaulting to yes. If told not to create it and it exists, the meta-function adds the values in the DSV data file to the existing data base.
- (Optional) That file's DSV delimiter character, defaulting to comma.
- (Optional) That file's comment string, defaulting to semicolon. Any line starting with it is ignored as a comment.
- (Optional) The label of the DSV item that has a unique value for each DSV row. If not given, the meta-function will generate a unique 1-n integer value to use for each DSV row.
- (Optional) The data base subscript with which to store the DSV data file's item delimiter character in the data base.
- (Optional) The data base subscript with which to store the DSV data file's column labels in the data base.
- (Optional) The (second) data base subscript with which to store each original DSV data line in the data base.
When called, the user meta-function will create the named XTRAN data base if it doesn't exist, and will load the DSV data into it from the named file as follows, based on the DSV data's labels row and on which DSV item number (if any) has unique values:
| 1st subscript |
2nd subscript |
Cell contents |
|---|---|---|
| <dlmchsb> | DSV data file's item delimiter character (optional) | |
| <labelsb> | DSV data file's column labels (optional) | |
| <uniqv1> | <label1> | <uniqv1>'s value for <label1>, if any |
| <uniqv1> | <label2> | <uniqv1>'s value for <label2>, if any |
| … | … | … |
| <uniqv1> | <linesb> | Original DSV data line (optional) |
| <uniqv2> | <label1> | <uniqv2>'s value for <label1>, if any |
| <uniqv2> | <label2> | <uniqv2>'s value for <label2>, if any |
| … | … | … |
| <uniqv2> | <linesb> | Original DSV data line (optional) |
| … | … | … |
where:
| <uniqvn> | is the value of the DSV column that has a unique value for each DSV row, or if that's not given, a unique 1-n integer |
| <labeln> | is the label for a data item (other than the unique one if given) |
| <dlmchsb> | (optional) is the text subscript with which to store the DSV file's item delimiter character in the data base |
| <labelsb> | (optional) is the text subscript with which to store the DSV column labels in the data base |
| <linesb> | (optional) is the (second) text subscript with which to store each original DSV data line in the data base |
The meta-function evaluates to the number of DSV data records stored in the data base, or to -1 if something went wrong.
Once the DSV data are loaded into your XTRAN data base, your data manipulation rules can quickly retrieve a <labeln>'s value for a <uniqvn>, as well as a <uniqvn>'s original DSV data line if you requested that, with a simple call to XTRAN's "get a data base cell's contents" built-in meta-function.
If you tell the meta-function to store the DSV data file's item delimiter character and column labels in the data base, you can create XTRAN rules that process data base contents in a very general way.
How can such powerful and generalized data manipulation be automated in only 3¼ hours and only 272 code lines of XTRAN rules? Because there is so much capability already available as part of XTRAN's rules language. These rules take advantage of the following functionality:
- Text file input and output
- Text manipulation
- Text formatting
- Delimited list manipulation
- Content-addressable data bases
- Creating new meta-functions written in meta-code, which we call user meta-functions
- Meta-variable and meta-function pointers
The input to XTRAN is shown untouched.
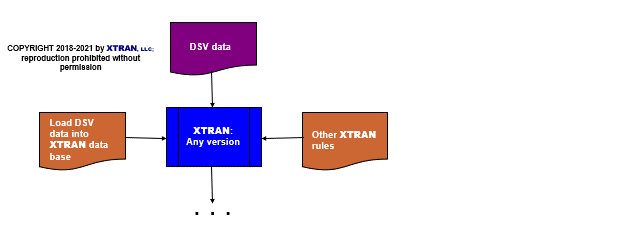
Process Flowchart
Here is a flowchart for this process, in which the elements are color coded:
- BLUE for XTRAN versions (runnable programs)
- ORANGE for XTRAN rules (text files)
- PURPLE for text data files
Example 1
For this example, we default the DSV delimiter character to comma and the
DSV comment string to semicolon. We also
specify "NAME" as the label of the column that contains
unique values.
DSV input data file:
; demd2d-1.dsv -- DSV data file for first example ; ; Label row: ; NAME,GENDER,AGE ; ; Data: ; Fred,M,43 Mary,F,19 George,M,55 ; ; End of demd2d-1.dsv
Data base contents after import:
| 1st subscript |
2nd subscript |
Cell contents |
|---|---|---|
"Fred" |
"AGE" |
"43" |
"Fred" |
"GENDER" |
"M" |
"George" |
"AGE" |
"55" |
"George" |
"GENDER" |
"M" |
"Mary" |
"AGE" |
"19" |
"Mary" |
"GENDER" |
"F" |
Example 2
For this example, we specify semicolon as the DSV delimiter character
and "??" as the DSV comment string. We again
specify "NAME" as the label of the column that contains
unique values; note that it's in a different position from the previous
example.
We also specify that the DSV data file's item delimiter character and column
labels are to be stored in the data base using the subscripts
"DLMCHR" and "LABELS".
We also specify that original DSV data lines are to be stored in the data
base using the subscript "DSVLIN".
DSV input data file:
?? demd2d-2.dsv -- DSV data file for second example ?? ?? Label row: ?? GENDER;AGE;NAME ?? M;;Fred F;19;Mary ;55;George ?? ?? End of demd2d-2.dsv
Note that "Fred" has no "AGE"
given, and that "George" has no
"GENDER" given.
Data base contents after import:
| 1st subscript |
2nd subscript |
Cell contents |
|---|---|---|
"DLMCHR" |
";" |
|
"LABELS" |
"GENDER;AGE;NAME" |
|
"Fred" |
"AGE" |
(none) |
"Fred" |
"DSVLIN" |
"M;;Fred" |
"Fred" |
"GENDER" |
"M" |
"George" |
"AGE" |
"55" |
"George" |
"DSVLIN" |
";55;George" |
"George" |
"GENDER" |
(none) |
"Mary" |
"AGE" |
"19" |
"Mary" |
"DSVLIN" |
"F;19;Mary" |
"Mary" |
"GENDER" |
"F" |
Example 3
For this example, we default the DSV delimiter character to comma and the DSV comment string to semicolon.
We don't specify a "unique values" column label, so the XTRAN meta-function assigns a unique 1-n integer to each DSV data row and uses that as the first subscript.
DSV input data file:
; demd2d-3.dsv -- Third DSV data file for demd2d-x.xxc ; Revised 2018-10-03.2153 by Stephen F. Heffner (Win10 on PREC7520) ; Created 2018-10-03 by Stephen F. Heffner (Win10 on PREC7520) ; ; Label row: ; GENDER,AGE,NAME ; M,55 F,19,Mary M,,George ; ; End of demd2d-3.dsv
Note that the first data line has no "NAME" value,
and "George" has no "AGE"
value.
Data base contents after import:
| 1st subscript |
2nd subscript |
Cell contents |
|---|---|---|
1 |
"AGE" |
"55" |
1 |
"GENDER" |
"M" |
1 |
"NAME" |
(none) |
2 |
"AGE" |
"19" |
2 |
"GENDER" |
"F" |
2 |
"NAME" |
"Mary" |
3 |
"AGE" |
(none) |
3 |
"GENDER" |
"M" |
3 |
"NAME" |
"George" |