XTRAN Example — Enable Sorting of DSV Data
Scenario — you have some delimiter separated value (DSV) data that you want to sort using a text sorting utility. Your task is complicated by the following issues:
- The delimited values are variable length.
- You want to sort some fields in ascending order and others in descending order.
- You want to sort some fields effectively right-justified (e.g. numeric data).
- You want to sort some fields case-sensitively and others case-insensitively.
XTRAN to the rescue!
The following example uses an XTRAN rules file comprising 300 non-comment lines of XTRAN's rules language ("meta-code") to prepare DSV data for sorting. The original rules took just over an hour to write and about an hour to debug. (That's right, just over two hours total!)
This is an example of XTRAN's ability to automate the manipulation of data as well as code.
You tell the rules, via environment variable values:
- Optionally, the data's DSV delimiting character, defaulting to comma.
- Optionally, the data file's comment character. If specified, the rules ignore any line that starts with it as a comment line. Note — comment lines will therefore not be in the output file.
- Which DSV fields are to be used for the sort, and in what order.
- For each sort field:
- Whether to sort the field in ascending or descending order.
- Optionally, whether to sort the field effectively right-justified within the maximum length seen in the data for the field. (It took only 30 minutes to add this feature to the XTRAN rules!)
- Optionally, whether to sort case-sensitive (the default) or case-insensitive. (It took only 15 minutes to add this feature to the XTRAN rules!)
The rules then prepend, to each DSV data line, the fields on which to sort:
- In the proper sorting order.
- With each descending sort field's text inverted to achieve that result.
- Padded to each field's maximum length in the data file
— with
zs if sorting the field descending, else with spaces, and at the beginning if the field is to be sorted right-justified, else at the end. - Forced to lower case if sorting the field case-insensitively.
- With the added field copies separated from the original data using a unique text token, to facilitate their removal after sorting.
You can then use a "dumb" sorting utility to do the
sorting, followed by a pass through a text processing utility such
as sed to remove the prepended sort field copies and separating
token, restoring the data to its original form (but now sorted as
requested).
We provide, with XTRAN, a BASH script to automate this process.
In the example below, we sort some DSV data:
- On the 4th field descending and right-justified, then
- On the 3rd field ascending and case-insensitive, then
- On the 1st field descending
The input to and output from XTRAN are untouched.
How can such powerful and generalized data manipulation be automated in about 3 hours and only 300 lines of rules? Because there is so much capability already available as part of XTRAN's rules language. The rules used for this example take advantage of the following functionality provided by that rules language:
- Text file input and output
- Text manipulation
- Delimited list manipulation
- Content-addressable data base
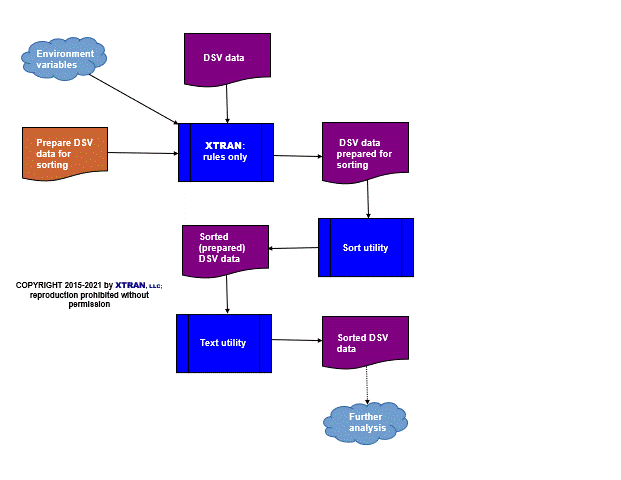
Process Flowchart
Here is a flowchart for this process, in which the elements are color coded:
- BLUE for XTRAN versions (runnable programs)
- ORANGE for XTRAN rules (text files)
- PURPLE for text data files
Input to XTRAN:
# dsvsrt.in -- Input file for demonstrating sorting of DSV data # def!abc12!RCD3!1,230!end3 abc!xyz1234!Rcd1!25!end1 abc!xyz1!rcd2!1,432!end2 xyz!xyz1!rcd2!1,230!end2 def!xyz1234!RCD1!25!end1 abc!xxyz!Rcd1!123,456!end3 # # End of dsvsrt.in
Output from XTRAN, as processed by the sort utility and the text utility:
abc!xxyz!Rcd1!123,456!end3 abc!xyz1!rcd2!1,432!end2 xyz!xyz1!rcd2!1,230!end2 def!abc12!RCD3!1,230!end3 abc!xyz1234!Rcd1!25!end1 def!xyz1234!RCD1!25!end1