XTRAN Example — Analyze HTML Tag & Attribute Usage
XTRAN treats HTML as a computer language, in which each tag, line or segment of nonmarkup text, or end tag is a "statement", and each tag attribute is a "statement attribute".
The following example uses an XTRAN rules file comprising 102 non-comment lines of XTRAN's rules language ("meta-code") to analyze and tally all tags and attributes used in HTML.
The HTML mining rules for this example can easily be enhanced
to produce DSV output that can be interactively queried using
existing XTRAN rules. ![]()
![]()
The following is an English paraphrase of the XTRAN rules used for this example.
For each HTML tag occurrence
Tally tag occurrence
For each of tag's attributes if any
Tally attribute occurrence for tag
Sort tags
For each HTML tag seen, alphabetically
Report tag tally
Sort attributes for tag
For each attribute seen for this tag, alphabetically
Report attribute tally
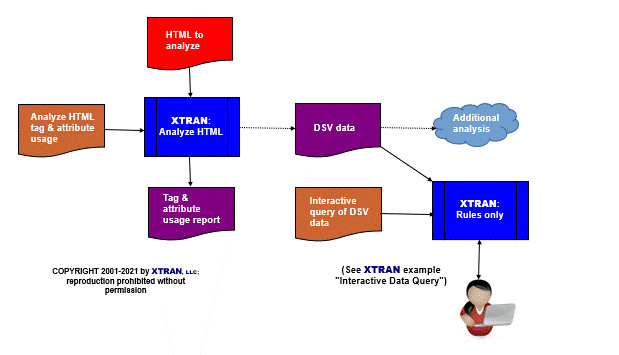
Process Flowchart
Here is a flowchart for this process, in which the elements are color coded:
- BLUE for XTRAN versions (runnable programs)
- ORANGE for XTRAN rules (text files)
- RED for
code - PURPLE for text data files
Output from XTRAN:
Running these rules on this HTML page generated the following XTRAN analysis output:
HTML Tag and Attribute Usage
!DOCTYPE 1
A 5
HREF 5
B 11
BODY 1
LINK 1
VLINK 1
BR 10
FONT 2
COLOR 1
FACE 2
SIZE 2
H3 1
HEAD 1
HR 2
SIZE 2
HTML 1
IMG 2
ALT 2
BORDER 1
HEIGHT 2
SRC 2
WIDTH 2
META 3
CONTENT 3
HTTP-EQUIV 1
NAME 2
P 7
ALIGN 1
PRE 2
TITLE 1