XTRAN Example — Markov analysis
Menu
Introduction
The following examples use XTRAN rules to perform a Markov analysis of state transition data. The rules can produce state transition frequency tallies and a frequency matrix — both in delimiter separated value (DSV) form.
The rules use an XTRAN content-addressable data base to store, organize, and tally the state transitions.
This shows how, with XTRAN, you can quickly automate sophisticated data analysis. The XTRAN rules used for these Markov analyses comprise only 95 code lines of meta-code, and took only a few hours to create and debug.
Input state transition data must be in the following DSV form, one transition per line:
<from-state><dlm><to-state>
where:
<from-state>
|
An alphanumeric token identifying the state moved from |
<dlm>
|
A one-character delimiter; defaults to comma |
<to-state>
|
An alphanumeric token identifying the state moved to |
Empty lines and lines starting with ; are ignored as
comments.
We then use another set of XTRAN rules comprising 111 code lines to transform the state transition frequency matrix produced by the first rule set into an HTML table. These rules accommodate any DSV data, optionally with a title and an initial label row.
How can such powerful and generalized data analysis and manipulation be automated in only a few hours and 95 lines of meta-code? Because there is so much capability already available as part of XTRAN's rules language. The rules used for these examples take advantage of the following functionality provided by that rules language:
- Text file input and output
- Text manipulation
- Delimited list manipulation
- Environment variable manipulation
- Content-addressable data bases
- "Per statement" recursive iterators
- Access to XTRAN's Internal Representation (XIR)
- Navigation in XIR
- XIR's language-independent properties
Scenario 1 — Statement type transitions in code
In this scenario, we first used an XTRAN rule set that analyzes and writes out statement type transitions in code. Those rules comprise 118 non-comment lines of XTRAN's rules language (meta-code); they took one hour to create and 12 minutes to debug. (That's right, just over an hour total!)
This particular example involves C++ code, but the rules are totally
language-independent. They allow you to specify, in a text file,
statement types you want them to ignore, which of course will vary by
language. In this case, we told them to ignore declaration
statements, {, and }.
The rules indicate when a statement type occurs at the beginning or end of
its code nesting level by specifying (none) as the "to"
or "from" state.
The input to XTRAN is untouched. The statement type transitions output has been edited to remove proprietary information, without changing its meaning; the rest of the output is untouched.
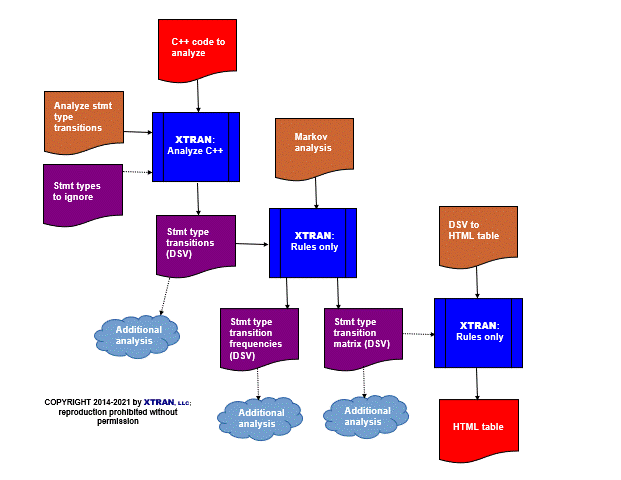
Process Flowchart
Here is a flowchart of this process, in which the elements are color coded:
- BLUE for XTRAN versions (runnable programs)
- ORANGE for XTRAN rules (text files)
- PURPLE for text data files
- RED for code files
Input to XTRAN:
int main(void)
{
short sh1, sh2;
try
{
for (sh1 = 1; sh1 < 9; ++sh1)
{
sh2 = sh1 + 3;
if (sh2 < 5)
{
printf("!");
bomb();
}
else
continue;
}
if (sh1 == 1)
throw(sh1);
}
catch (short shp)
{
fnc(shp);
fnc(2);
}
return;
}
Output from first XTRAN rule set — statement type transitions:
(none),try (none),for (none),expr expr,if (none),expr expr,expr expr,(none) if,else else,(none) (none),continue continue,(none) for,if if,(none) (none),throw throw,(none) try,catch (none),expr expr,expr expr,(none) catch,return return,(none)
Output from second XTRAN rule set — transition frequencies:
(none),continue,1 (none),expr,3 (none),for,1 (none),throw,1 (none),try,1 catch,return,1 continue,(none),1 else,(none),1 expr,(none),2 expr,expr,2 expr,if,1 for,if,1 if,(none),1 if,else,1 return,(none),1 throw,(none),1 try,catch,1
Output from second XTRAN rule set — transition frequency matrix:
State,(none),catch,continue,else,expr,for,if,return,throw,try (none),0,0,1,0,3,1,0,0,1,1 catch,0,0,0,0,0,0,0,1,0,0 continue,1,0,0,0,0,0,0,0,0,0 else,1,0,0,0,0,0,0,0,0,0 expr,2,0,0,0,2,0,1,0,0,0 for,0,0,0,0,0,0,1,0,0,0 if,1,0,0,1,0,0,0,0,0,0 return,1,0,0,0,0,0,0,0,0,0 throw,1,0,0,0,0,0,0,0,0,0 try,0,1,0,0,0,0,0,0,0,0
Output from third XTRAN rule set — HTML table:
Markov Analysis Results
| State |
Transitions to (none)
|
Transitions to catch
|
Transitions to continue
|
Transitions to else
|
Transitions to expr
|
Transitions to for
|
Transitions to if
|
Transitions to return
|
Transitions to throw
|
Transitions to try
|
|---|---|---|---|---|---|---|---|---|---|---|
(none)
|
0 | 0 | 1 | 0 | 3 | 1 | 0 | 0 | 1 | 1 |
catch
|
0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
continue
|
1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
else
|
1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
expr
|
2 | 0 | 0 | 0 | 2 | 0 | 1 | 0 | 0 | 0 |
for
|
0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
if
|
1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
return
|
1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
throw
|
1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
try
|
0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Scenario 2 — Vehicle speed transitions
To show that the XTRAN rules being used are not specific to any computer language, or even to being used on a computer language, here is a scenario that deals with speed transitions hypothetically observed by sampling the progress of a vehicle.
The input to and output from XTRAN are untouched.
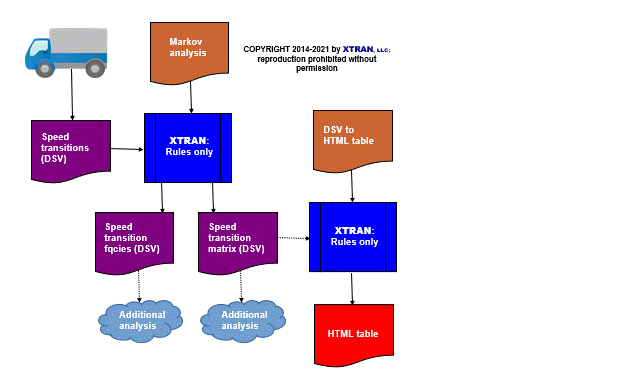
Process Flowchart
Here is a flowchart of this process, in which the elements are color coded:
- BLUE for XTRAN versions (runnable programs)
- ORANGE for XTRAN rules (text files)
- PURPLE for text data files
- RED for code files
Input to XTRAN:
; Input data for Markov analysis ; stopped,slow slow,slow slow,fast fast,fast fast,fast fast,slow slow,slow slow,fast fast,slow slow,slow slow,stopped stopped,stopped stopped,slow slow,slow slow,stopped stopped,slow slow,fast fast,fast fast,slow slow,stopped
Output from first XTRAN rule set — transition frequencies:
fast,fast,3 fast,slow,3 slow,fast,3 slow,slow,4 slow,stopped,3 stopped,slow,3 stopped,stopped,1
Output from first XTRAN rule set — transition frequency matrix:
State,fast,slow,stopped fast,3,3,0 slow,3,4,3 stopped,0,3,1
Output from second XTRAN rule set — HTML table:
Markov Analysis Results
| State |
Transitions to fast
|
Transitions to slow
|
Transitions to stopped
|
|---|---|---|---|
fast
|
3 | 3 | 0 |
slow
|
3 | 4 | 3 |
stopped
|
0 | 3 | 1 |