XTRAN Example — Tally DSV Values by Field Name
Scenario — you want to tally the occurrences of field values in delimiter separated value (DSV) data.
XTRAN to the rescue!
The following example uses an XTRAN rules file comprising 86 non-comment lines of "meta-code" (XTRAN's rules language) to tally field values by field name in DSV data.
The rules took less than one hour to write and ½ hour to debug. (That's right, less than 1½ hours total!)
You specify to the rules, via environment variable values:
- The name of a DSV data file to process, starting with a field label row; empty lines and lines starting with a semicolon are ignored
- The name of the output file to create
- (optionally) The DSV delimiting character, defaulting to comma
The rules output the resulting value tallies in the following DSV format (assuming the DSV delimiting character is defaulted to comma):
<label>,<value>,<tally>
where:
<label>
|
Field's label, from the label row |
<value>
|
Field's value |
<tally>
|
Number of times <value> occurs
for <label>
|
For instance, given the following DSV data input:
; Label row: ; make,color,year ; ; Data: ; Chrysler,red,2013 Cadillac,black,2015 Ford,blue,2015 Cadillac,white,2015 Ford,white,2013 Chrysler,black,2013 Ford,white,2014
The output will be
color,black,2 color,blue,1 color,red,1 color,white,3 make,Cadillac,2 make,Chrysler,2 make,Ford,3 year,2013,3 year,2014,1 year,2015,3
How can such powerful and generalized data manipulation be automated in less than 1½ hours and only 86 code lines of XTRAN rules? Because there is so much capability already available as part of XTRAN's rules language. These rules take advantage of the following functionality:
- Text file input and output
- Text manipulation
- Text formatting
- Delimited list manipulation
- Environment variable manipulation
- Content-addressable data bases
- Creating new meta-functions written in meta-code, which we call user meta-functions
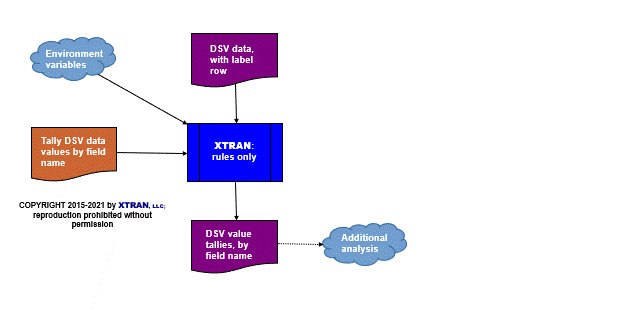
Process Flowchart
Here is a flowchart for this process, in which the elements are color coded:
- BLUE for XTRAN versions (runnable programs)
- ORANGE for XTRAN rules (text files)
- PURPLE for text data files