XTRAN Example — Manipulate Dependency Trees
Menu
- Introduction
- Scenario 1: Include file dependencies
- Scenario 2: Module/function calling tree
- Scenario 3: Genealogy
Introduction
Software engineers often encounter dependency tree situations, in which some entities depend on others. In other words, some entities (invokers) invoke other entities (invokees), thereby forming a dependency tree. Some examples:
- File includes
- Function calls
- Macro invocations
In all three cases, an invokee can itself be an invoker — an included file can itself include files, a called function can itself call functions, and a macro can itself invoke macros. This creates indirect (and potentially recursive) dependencies as well as direct ones.
Sometimes you want to find out which entities depend on which other entities. For instance, suppose you change an included file, and you want to find out which modules need to be recompiled. This requires that you find not only direct dependencies, but indirect ones as well.
The following demonstrations used an XTRAN rule set ("meta-code") to determine, given a set of dependencies and a set of invokees, all of those invokees' invokers.
The rules first read invoker/invokee dependency information, which is typically extracted from a body of code automatically, using XTRAN code analysis rules. These rules then read a list of invokees to do, analyze the dependency tree, and output the names of those invokees' invokers. They offer the following options:
- In addition to direct (parent) dependencies, also list all indirect dependencies.
- Show the lineage for each dependency.
These rules comprise 144 non-comment lines of meta-code, and were created and debugged in about six hours. (That's right, only six hours!)
Note that in these examples, the entities are modules, or included files, or people. But they could also be functions or any other type of entity. Since the XTRAN rules are language-independent, they can be used to analyze any kind of dependency, for any language (or no language at all).
Since these XTRAN rules read and parse only text, we use a version of XTRAN that has a parser for its own rules language, but not for any other language.
How can such powerful and generalized data manipulation be automated in only 6 hours and 144 lines of XTRAN rules? Because there is so much capability already available as part of XTRAN's rules language. These rules take advantage of the following functionality:
- Text file input and output
- Text manipulation
- Text formatting
- Delimited list manipulation
- Environment variable manipulation
- Content-addressable data bases
- Creating new meta-functions written in meta-code, which we call user meta-functions
- Recursive user meta-functions
- Meta-variable and meta-function pointers
Scenario 1: Include file dependencies
Suppose your code has the following include tree:
- module1 includes:
- include1
- include3
- module2 includes:
- include2
- module3 includes:
- include1
- module4 includes:
- include4
- include4 includes:
- include1
We have used an existing set of XTRAN code analysis rules to automatically extract this information from the code in the following form:
module1,include1 module1,include3 module2,include2 module3,include1 module4,include4 include4,include1
We then specify to the XTRAN rules that we
want all direct and indirect dependencies
for include1 and include3. Since we're only
interested in modules that must be recompiled, we also
tell XTRAN to suppress output of entities whose
names start with include.
Process Flowchart
Here is a flowchart for this process, in which the elements are color coded:
- BLUE for XTRAN versions (runnable programs)
- ORANGE for XTRAN rules (text files)
- RED for
code - PURPLE for text data files

Output from XTRAN:
module1 module3 module4
Note that the rules picked up module4 as an indirect dependency of
include1, via include4.
Scenario 2: Module/function calling tree
Suppose you're changing a function's calling sequence, and you want a list of all modules that call that function. Here's your module/function calling tree:
- module1 calls:
- function1
- function3
- module2 calls:
- function2
- function5
- module3 calls:
- function1
- module4 calls:
- function4
You have used a set of XTRAN code analysis rules to automatically extract this information from the code in the following form:
module1,function1 module1,function3 module2,function2 module2,function5 module3,function1 module4,function4
You now ask the XTRAN rules for all modules that
call function2 and function4. Note that
in this case we specify only direct
(not indirect) dependencies.
Process Flowchart
Here is a flowchart for this process, in which the elements are color coded:
- BLUE for XTRAN versions (runnable programs)
- ORANGE for XTRAN rules (text files)
- RED for
code - PURPLE for text data files
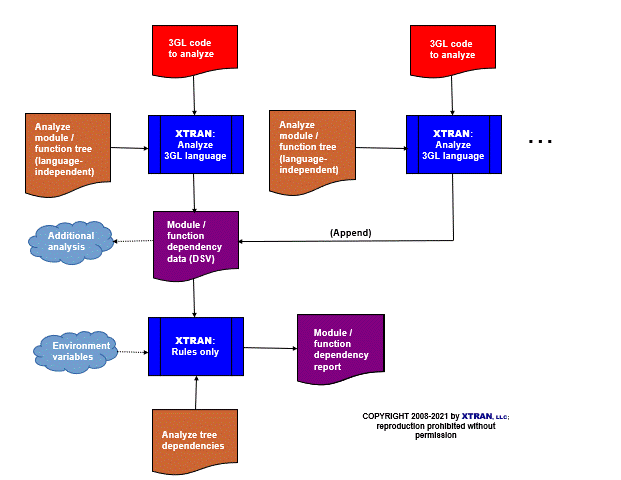
Output from XTRAN:
module2 module4
Scenario 3: Genealogy
And finally, just to show that these XTRAN rules can handle any kind of dependency information, suppose your family tree is, as far as you know it:
- Harry married Jane and they had three children:
- Tom
- Edward
- Anne
- Edward married Sandy and they had one child:
- Fred
- Tom married Mary and they had two children:
- Elizabeth
- George
- Elizabeth married Albert and they had one child:
- You
We represent this dependency information as follows:
Harry,Tom Harry,Edward Harry,Anne Jane,Tom Jane,Edward Jane,Anne Edward,Fred Sandy,Fred Tom,Elizabeth Tom,George Mary,Elizabeth Mary,George Elizabeth,me Albert,me
We now ask the XTRAN rules for all of your ancestors, both direct and indirect, showing the lineage in each case.
Process Flowchart
Here is a flowchart for this process, in which the elements are color coded:
- BLUE for XTRAN versions (runnable programs)
- ORANGE for XTRAN rules (text files)
- PURPLE for text data files
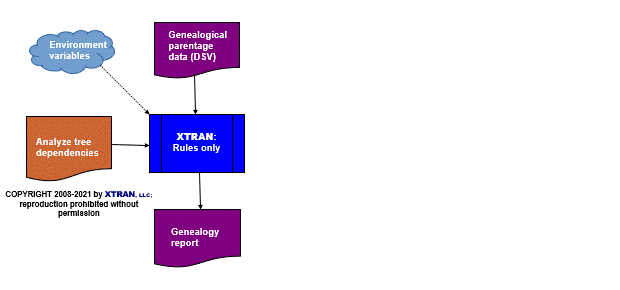
Output from XTRAN:
Harry -> Tom -> Elizabeth -> me Jane -> Tom -> Elizabeth -> me Tom -> Elizabeth -> me Mary -> Elizabeth -> me Elizabeth -> me Albert -> me