XTRAN Example — Analyze Word Phrases in Text
Menu
- Introduction
- Strategy
- Common XTRAN input
- Scenario 1 — Analyze significant word pairs
- Scenario 2 — Analyze for sequences of interesting words
- Scenario 3 — Analyze "keyword in context" (KWIC)
Introduction
Usage patterns of text phrases are important in a broad range of pursuits. Some examples:
- Detecting plagiarism, useful to educators and publishers.
- Detecting the automated creation of prose, e.g. bot-generated reviews on the Web.
- Determining if multiple documents have the same author, e.g. in forensic analysis of terrorist manifestos and Web traffic, or in historical analysis of literature (such as the notorious Shakespeare vs. Bacon controversy).
- Studying the use of idioms in prose, e.g. analyzing style or regional influences.
- Determining prose's level of sophistication (reading level).
One way to approach analysis of text phrase usage is to use Markov analysis — the frequency with which sequences of words occur. By extending the length of transition chains beyond the usual 2, this can detect repetition of entire phrases. And because it analyzes a sequence of delimited tokens, it is insensitive to such physical text issues as line breaks, indentation, white space, etc.
Strategy
The following example uses an XTRAN rules file comprising 243 non-comment lines of "meta-code" (XTRAN's rules language) to analyze word phrases in text.
The rules took 4¼ hours to write and 4½ hours to debug. (That's right, less than 9 hours total!)
The rules use an XTRAN content-addressable data base to store, organize, and tally the word transitions.
You can optionally specify, to the XTRAN rules, the following analysis controls via environment variables:
- The minimum and maximum phrase length to process.
- The punctuation characters that end a phrase. These will vary for different languages, and also for different types of analysis.
- Either (but not both) of the following:
- A list of insignificant words the rules are to ignore.
- A list of significant words to which the rules are to limit the analysis, ignoring all other words.
- A list of filter words; if specified, a phrase will only be processed if it contains at least one of these words.
- Whether or not to suppress analysis of shorter phrases that prefix longer ones.
- To eliminate case issues, all words are normally forced to lower case; do not force them.
The XTRAN rules output, for each phrase that satisfied the analysis controls specified, a count of its occurrences, zero-filled for sorting, followed by the phrase itself.
The XTRAN rules used for this example are not specific to analyzing prose text; they can be used unchanged to analyze any sequence of delimited tokens. So they effectively constitute a generalized Markov analysis engine.
How can such powerful and generalized analysis be automated in less than 9 hours and only 243 lines of rules? Because there is so much capability already available as part of XTRAN's rules language. The rules used for this example take advantage of the following functionality provided by that rules language:
- Text file input and output
- Text manipulation
- Text formatting
- Delimited list manipulation
- Environment variable manipulation
- Content-addressable data bases
- Creating new meta-functions written in meta-code, which we call user meta-functions
- Meta-variable and meta-function pointers
The three scenarios that follow all use exactly the same rules, taking advantage of the controls described above to determine the nature of the analysis.
The input to and outputs from XTRAN are untouched.
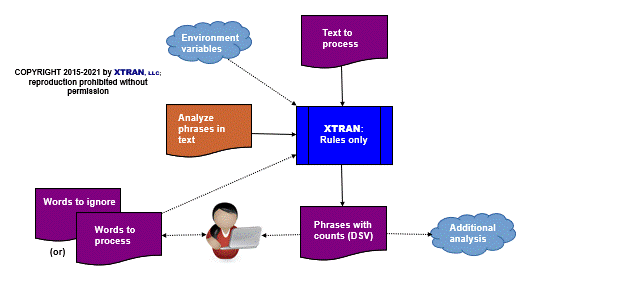
Process Flowchart
Here is a flowchart for this process (which is the same for all three scenarios), in which the elements are color coded:
- BLUE for XTRAN versions (runnable programs)
- ORANGE for XTRAN rules (text files)
- PURPLE for text data files
Common XTRAN Input
The text input to XTRAN for analysis is the same for all three scenarios:
This is a sample of prose we will process with XTRAN rules. It spans a number of lines, and has a few interesting words and phrases in it for the rules to analyze. The quick brown fox jumped over the lazy dog. I regret that I have but one life to give for my country. Give me liberty or give me death. A penny saved is a penny earned. Now we will repeat a few phrases to show how the XTRAN rules tally them. A penny saved is a penny earned. I regret that I have but one life to give for my country. A penny not saved is a penny wasted. The lazy dog woke up and chased the quick brown fox away. I regret that I have but one penny to give to charity, but a penny is better than nothing.
Scenario 1 — Analyze Significant Word Pairs
In this scenario, we are interested in the occurrence of significant word pairs. This is useful, for example, in analyzing patterns of adjectives and adverbs used to modify nouns and verbs.
To accomplish this, we tell the XTRAN rules to:- Ignore a list of what we consider insignificant words.
- Analyze only pairs of the remaining words, by limiting word transition chains to a length of 2.
Input to XTRAN — words to ignore:
a is the and it them but me this few my to for now we has of will have or with how over in that
(By the way, we used XTRAN rules to format
the list above into columns from its "one item per line" file.)
![]()
![]()
Output from XTRAN:
0000001,sample prose 0000001,prose process 0000001,process xtran 0000002,xtran rules 0000001,spans number 0000001,number lines 0000001,interesting words 0000001,words phrases 0000001,phrases rules 0000001,rules analyze 0000002,quick brown 0000002,brown fox 0000001,fox jumped 0000001,jumped lazy 0000002,lazy dog 0000003,i regret 0000003,regret i 0000003,i one 0000002,one life 0000002,life give 0000002,give country 0000001,give liberty 0000001,liberty give 0000001,give death 0000002,penny saved 0000003,saved penny 0000002,penny earned 0000001,repeat phrases 0000001,phrases show 0000001,show xtran 0000001,rules tally 0000001,penny not 0000001,not saved 0000001,penny wasted 0000001,dog woke 0000001,woke up 0000001,up chased 0000001,chased quick 0000001,fox away 0000001,one penny 0000001,penny give 0000001,give charity 0000001,penny better 0000001,better than 0000001,than nothing
Scenario 2 — Analyze for Sequences of Interesting Words
In this scenario, we are interested in the occurrence of chains of specific words, ignoring all intervening words. This is useful, for example, in analyzing the expression of concepts that are of interest, and that are typically described using well-known combinations of words.
This analysis can also be useful in identifying ambiguosity introduced into prose by the use of homonyms, and to establish how to automatically unoverload such homonyms using their context.
To accomplish this, we tell the XTRAN rules to:
- Process only words that are significant for our analysis.
- Analyze all sequences of such words, of any length.
Input to XTRAN — words to process:
analyze country death liberty life penny phrases rules words xtran
Output from XTRAN:
0000001,xtran rules 0000002,life country 0000001,liberty death 0000003,penny penny 0000001,phrases xtran rules 0000001,words phrases rules analyze
Scenario 3 — Analyze "Keyword in Context" (KWIC)
In this scenario, we are interested in seeing the context in which a series of keywords are used in the text being analyzed.
To accomplish this, we tell the XTRAN rules to:
- Process all words.
- Process phrases of any length.
- Process only phrases that contain at least one of our keywords.
Input to XTRAN — keywords to do:
death fox penny
Output from XTRAN:
0000001,give me liberty or give me death 0000002,a penny saved is a penny earned 0000001,but a penny is better than nothing 0000001,a penny not saved is a penny wasted 0000001,the quick brown fox jumped over the lazy dog 0000001,the lazy dog woke up and chased the quick brown fox away 0000001,i regret that i have but one penny to give to charity