XTRAN Example — Cross Link & Index HTML Documents
Anatomy of a Complex HTML Document with Variants
A document (or Web site) written in HTML may comprise many "chapters" (HTML source files), typically front-ended by a title page / Table of Contents that links to all of the chapter files and an index. An example is the XTRAN User's Manual.
In some situations, we may have variants of the document, in which not all chapters participate in every variant. For instance, in the case of the XTRAN User's Manual, each XTRAN licensee receives a variant that is tailored for the licensed activity. So someone licensing XTRAN for, say, translation of PL/I to C++ will get a variant of the XTRAN User's Manual that contains only those chapters relevant to that activity. Someone else licensing XTRAN for, say, analysis of mainframe assembler will receive a different variant, containing a different selection of chapters.
Each variant must have its own title page and a table of contents that links to the chapters participating in that variant. The variant must also have an index showing only those index entries that are in the participating chapters..
Objective: Cross Link and Index HTML Documents
For maximum convenience of use, we would like for each occurrence of a significant term anywhere in a variant of the document to be cross linked to that term's definition (a practice widely seen in Wikis). That definition may well be in a different chapter than the reference. However, we don't want to cross link the occurrence of a term whose definition is in a chapter not included in our variant. We also don't want to cross link a term occurrence that's in close proximity to the term's definition.
In addition, we want to have a thorough alphabetical index at the end of our document. Obviously, it should include only entries whose bookmarks are in chapters included in our variant. For the document reader's convenience, we would also like for each index entry to show the section and chapter in which it occurs; this is commonly known as a Key Word in Context (KWIC) index. And we would like to have, at the index's start, a letter-by-letter index to the index.
As any professional indexer will tell you, the hard work is deciding which
terms in the document to index. Although many attempts have been made to
automate this process, with some success (including with
XTRAN
![]()
![]() ), the only
way to guarantee a really good job is for a knowledgeable human being to
carefully control the indexing process and "fine tune" the final
product.
), the only
way to guarantee a really good job is for a knowledgeable human being to
carefully control the indexing process and "fine tune" the final
product.
However, once we have inserted the index entries into the document's chapters, we can automate the rest of the work — cross referencing item occurrences in a document variant's chapters, and generating the document variant's index. We can also automate generating each variant's title page / Table of Contents.
How XTRAN and TemplaGen Can Help
HTML is one of many computer languages XTRAN manipulates.
XTRAN represents each tag, segment of nonmarkup text,
and end tag as an HTML "statement", and represents each attribute of
a tag as a "statement attribute", possibly with a value
(following =).
XTRAN's Internal Representation (XIR) of HTML is essentially the same as for all other computer languages XTRAN manipulates, including assemblers, 3GLs such as COBOL and C++, 4GLs such as RPG and Natural, meta-data languages such as XML, scripting languages, Web languages, data base languages such as SQL, and special-purpose languages. This means that the full power of XTRAN's rules language is available to manipulate HTML.
This example employs 1,068 code lines of XTRAN's rules language (which we also call "meta-code"). It shows how we can use several versions of XTRAN to automatically cross link and index all occurrences of specified text items. The example assumes that the target to which each item is to be cross linked and indexed is marked with a bookmark that has an appropriate name. Such a bookmark may or may not enclose related text.
We use two (illegal) HTML <a> attributes in the
bookmarks, nolink and noindex, to control, in the
original HTML files, whether each bookmark is cross linked and/or
indexed. We remove these attributes in the process of cross linking, so
they don't show up in the final document variant.
We also use a set of XTRAN styling rules for rendering HTML that specifies, for each tag, whether it and its end tag (if any) are to get preceding and/or following line breaks in the output.
How can such powerful and generalized HTML manipulation be automated in only 1,068 code lines of XTRAN rules? Because there is so much capability already available as part of XTRAN's rules language. These rules take advantage of the following functionality:
- Text file input and output
- Text manipulation
- Text formatting
- Delimited list manipulation
- Environment variable manipulation
- Content-addressable, in-memory data bases
- "Per statement" recursive iterator
- Statement and expression pattern matching and replacement
- Access to XTRAN's Internal Representation (XIR)
- Navigation in XIR
- Creating new meta-functions written in meta-code, which we call user meta-functions
- Meta-variable and meta-function pointers
TemplaGen, our no-code / low-code template-driven and data-driven artifact generator, provides the means to automate the generation of the artifacts we need — both HTML files and other text artifacts. TemplaGen is itself written in XTRAN's rules language.
Strategy
Our strategy is as follows:
- We maintain, in our XTRAN Repository, what activity type (analysis, re-engineering, translation, or rules-only) each variant documents, and what computer language or combination of languages (if any) it documents. The XTRAN Repository also contains, for each chapter of our Master Document, what variant types it is for and what computer language(s) (if any) it documents.
- We maintain a Master Document comprising all chapters for all document
variants, in the form of TemplaGen HTML
templates. We insert, into all of these templates, bookmarks in the
form:
<a name="xxx" [[nolink]] [[noindex]]>[[<text>]]</a>
...where the optional
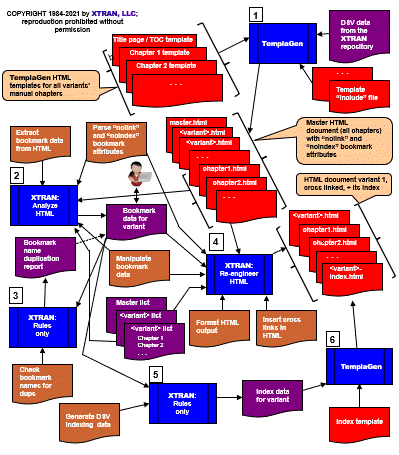
nolinkand/ornoindexattributes control our cross linking and indexing activities. (They're not legal HTML, but they will be removed from the final document pages, having served their purpose.) We use TemplaGen to generate our Master Document's HTML files from the individual chapter templates plus data from our XTRAN Repository (Step 1 in the process flowchart below). Doing so provides us many advantages, including the following:
- Our XTRAN User's Manual variants are automatically synchronized with any changes we make in our XTRAN Repository, which also feeds TemplaGen generation of XTRAN's code and DevOps artifacts. This guarantees that XTRAN's code, documentation, and build process don't get out of sync with each other, eliminating both error-prone "parallel maintenance" and significant amounts of developer labor.
- We can use TemplaGen templates to generate some HTML files almost exclusively with data exported from our XTRAN Repository.
- We can use "include" files, without scripting, for repeated chunks of HTML such as page headers. The contents of such a file can be tailored at include time by embedding environment variable names in the included file, which TemplaGen will replace with the variables' values, and setting those variables in the TemplaGen template prior to the include.
- Similarly, we can use "include" files for common operations such as pulling in a reference data base exported from our XTRAN repository for use by our TemplaGen templates during the HTML generation process.
- We can apply TemplaGen's rich set of data selection, transformation, and editing capabilities to our data when generating our HTML.
All changes to the Master Document are made to its TemplaGen templates.
- We use a TemplaGen template to create, for each
document variant, a text file named
<variant>.namthat lists all of the chapter HTML files that comprise that variant. We use this file to drive the script that generates each variant of our XTRAN User's Manual. - We also use
<variant>.namto drive a TemplaGen template that generates, for each document variant, a title page named<variant>.htmlwith a Table of Contents that links to the chapter HTML files that comprise that variant, and also links to the index we will create for that variant. We run XTRAN's HTML analysis version with rules that extract bookmark data from all chapters of the Master Document that comprise our document variant, creating a bookmark data file used by all subsequent steps to generate this variant. This data file includes, for each bookmark in our variant's chapters:
- The bookmark name.
- Text included in the bookmark, or if none, the bookmark name again.
- The most recent header text preceding the bookmark (what section it's in). Exception — if the bookmark immediately precedes a header, we use that header's text.
- The title of the chapter the bookmark is in.
- The name of the HTML file the bookmark is in.
- Whether the bookmark is to be cross linked and/or indexed, based on the
presence or absence of
nolinkand/ornoindexattributes in the original HTML. If it is to be neither cross linked nor indexed, we don't record an entry for it.
-
Because cross linking won't work if there are duplications among the items to be cross linked, we run XTRAN's rules-only version with rules that find and report any such duplications (either exact or embedded in a longer bookmarked term) in the variant's bookmark data file. We then edit the data file and reorder bookmark data as needed to eliminate embedded duplications. We also edit the Master Document HTML files to eliminate exact bookmarked term duplications. We rerun XTRAN with the duplication checking rules after every change, iterating this process until it reports no duplications.
We run XTRAN's HTML re-engineering version with rules that read this variant's bookmark data, then find each occurrence of each bookmark name in the chapters comprising the variant and cross link that occurrence to the relevant bookmark. (This automatically excludes occurrences of names whose bookmarks are in chapters not included in our variant.) For example, assume that there is, in
chapter1.html:<a name="XTRAN">XTRAN</a>
An occurrence, perhaps in a different chapter file included in our variant, of
XTRAN
...in nonmarkup text will be replaced with
<a href="chapter1.html#XTRAN">XTRAN</a>
...creating a link the reader can follow to the bookmark in
chapter1.html.Exception — if a bookmarked name occurs just before or in the bookmark's most recent header, the rules don't insert a cross link, since the occurrence is in the same area as the bookmark.
Note that if the bookmark occurrence is in the same chapter file as the bookmark's definition, we don't need to specify that file name, resulting in:
<a href="#XTRAN">XTRAN</a>
...and the process does this automatically.
This step also removes the (illegal)
nolinkandnoindexattributes from the bookmarks. We write the resulting cross linked HTML chapter to the variant's subdirectory.For each document variant, we run XTRAN's "rules only" version with rules to extract "initial letter" information we'll need to generate the "index to the index" in our variant's index.
Finally, we run TemplaGen with a template that reads indexing data for that variant and generates an HTML "key word in context" index for it, excluding bookmarks in chapters not included in our variant, and with an alphabetical "index to the index" at its start. We write the resulting HTML index to the variant's subdirectory as
<variant>-index.html, satisfying the link to it in<variant>.html, the variant's title page / Table of Contents.- BLUE for XTRAN and TemplaGen (runnable programs)
- ORANGE for XTRAN rules (text files)
- RED for HTML files and TemplaGen templates for them
- PURPLE for text data files
- variant1.html — Title page for variant 1,
with links to its chapters and to the index we will create for it;
automatically generated with a TemplaGen
template
- variant2.html — Title page for variant 2,
with links to its chapters and to the index we will create for it;
automatically generated with a TemplaGen
template
- chapter1.html — Participates in variants 1
and 2
- chapter2.html — Participates in variants 1
and 2
- chapter3.html — Participates in variant 2
only
- chapter4.html — Doesn't participate in either variant 1 or variant
2
Once we have used TemplaGen to generate all of our Master Document's chapters (Step 1), the actual manual generation process for a variant has the following major steps (numbered in the flow chart below):
Process Flowchart
Here is a flowchart of this process, in which the elements are color coded:
Input to, and Output from, XTRAN
This example uses a "mini" version of the XTRAN User's Manual to show the effects of the cross linking and indexing procedures. This "mini" version is not proprietary; the actual XTRAN User's Manual is proprietary and requires a nondisclosure agreement. Also, this "mini" version is for demonstration purposes only and is not necessarily current. Therefore, its contents do not constitute any representation by XTRAN, LLC about XTRAN.
The actual XTRAN User's Manual (including all variants) has more than 1,200 bookmarks in over 50 HTML files containing more than 20,000 nonmarkup text items; cross linking a variant of it involves as many as 25 million checks for cross links to insert.
Master Document
Variant Chapter Lists
These text files, which are automatically generated with a TemplaGen template from data we export from the XTRAN Repository, are read by scripts, XTRAN rules, and TemplaGen templates to determine which chapters participate in which document variants.
master.nam
; master.nam — Chapters in XTRAN User's Manual, all variants ; Created 2002-02-09.1305 by TemplaGen from the XTRAN Repository ; chapter1.html chapter2.html chapter3.html chapter4.html ; ; End of master.nam
variant1.nam
; variant1.nam — Chapters in XTRAN User's Manual variant 1 ; Created 2002-02-09.1305 by TemplaGen from the XTRAN Repository ; chapter1.html chapter2.html ; ; End of variant1.nam
variant2.nam
; variant2.nam — Chapters in XTRAN User's Manual variant 2 ; Created 2002-02-09.1305 by TemplaGen from the XTRAN Repository ; chapter1.html chapter2.html chapter3.html ; ; End of variant2.nam
Resulting Document Variant 1
- variant1.html — Title page / Table of
Contents for variant 1
- chapter1.html — with cross links for
terms bookmarked in Variant 1 chapters
- chapter2.html — with cross links for
terms bookmarked in Variant 1 chapters
- xtr-index.html — index created with
XTRAN and TemplaGen for this
variant