XTRAN Example — Mine Web Pages for Keywords
Scenario: You know that to help your Web site show up in searches, you need to include significant keywords on each page. So you want to identify and catalog the significant words in your site that the Web spiders will index.
XTRAN to the rescue!
The following example uses an XTRAN rules file comprising 175 non-comment lines of XTRAN's rules language ("meta-code") to analyze HTML and count significant words in nonmarkup text — English in this example, but the rules can handle Web pages in any language.
These rules are actually an adaptation of our existing
XTRAN rules to count words in text
![]()
![]() . It
took less than one hour to adapt those rules to mine HTML,
and ten minutes to debug the result. (That's right, about an
hour total!)
. It
took less than one hour to adapt those rules to mine HTML,
and ten minutes to debug the result. (That's right, about an
hour total!)
The results output is alphabetically ordered and in delimiter separated value (DSV) form, suitable for input to a spreadsheet or data base for further analysis, graphing, etc.
The HTML mining rules for this example can easily be enhanced
to produce DSV output that can be interactively queried using
existing XTRAN rules. ![]()
![]()
The rules force all analyzed text to lower case before counting the words, to avoid issues with upper vs. lower case.
The rules allow you to optionally specify, via environment variables:
- The characters that delimit words; the default is
<SPACE><TAB>,:;.?!()[]{}<>^'"+*/=%& - The name of a text file containing either (but not both):
- Words to ignore in the counts. Typically these are pronouns, connectives, prepositions, etc., whose counts are not interesting.
- Words to report in the counts, ignoring all other words. This means you can use these same rules to tally occurrences of specific words across a Web site.
- The name of a text file containing a series of regular expressions to match HTML tags whose contents are to be ignored.
- Whether to write a label row at the beginning of the output file (a common practice for DSV data); the default is no label row.
- Whether to prefix each word count with the module name; the default is no module name.
We have actually used these rules to mine each page of this very Web site for significant words, accumulating a list of about 3,300 words to ignore across the entire site.
We then used existing XTRAN rules
to summarize keyword occurrences across the entire site, giving
about 7,000 occurrences of about 850 keywords.
![]()
![]()
How can such powerful HTML analysis be automated in only one hour and 175 lines of rules? Because there is so much capability already available as part of XTRAN's rules language. The rules used for this example take advantage of the following functionality provided by that rules language:
- Text file input and output
- Text manipulation
- Text formatting
- Delimited list manipulation
- Regular expression matching
- Environment variable manipulation
- Content-addressable data bases
- "Per statement" recursive iterators
- Access to XTRAN's Internal Representation (XIR)
The input to and output from XTRAN are untouched.
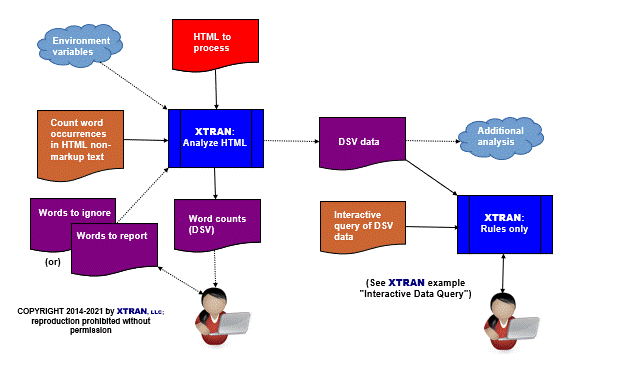
Process Flowchart
Here is a flowchart for this process, in which the elements are color coded:
- BLUE for XTRAN versions (runnable programs)
- ORANGE for XTRAN rules (text files)
- RED for
code - PURPLE for text data files
Input to XTRAN — Web page to process (rendered):
Dangerous Dan's Nocturnal Aviation Company
Do you need to get somewhere discreetly, under the cover of darkness? Dangerous Dan can get you there! Our airplanes are stealth equipped, so your adversary's radar won't find you. They run without lights, so our pilots are especially vigilant to avoid collisions with other aircraft, mountains, etc. They are also experts in evasive maneuvers.
We serve snacks, assuming clear weather and no hostile fire.
And if you need discreet ground transportation at your destination, be sure to check out Dangerous Dan's Nocturnal Limousine Service! Our limousines are also stealth equipped, to avoid police radar, and our drivers are thoroughly trained in evasive driving.
Input to XTRAN — Web page to process (raw HTML):
<h4 align="center">Dangerous Dan's Nocturnal Aviation Company</h4> <p>Do you need to get somewhere discreetly, under the cover of darkness? <b>Dangerous Dan</b> can get you there! Our airplanes are stealth equipped, so your adversary's radar won't find you. They run without lights, so our pilots are especially vigilant to avoid collisions with other aircraft, mountains, etc. They are also experts in evasive maneuvers.</p> <p>We serve snacks, assuming clear weather and no hostile fire.</p> <p>And if you need discreet ground transportation at your destination, be sure to check out <b>Dangerous Dan's Nocturnal Limousine Service</b>! Our limousines are also stealth equipped, to avoid police radar, and our drivers are thoroughly trained in evasive driving.</p>
Input to XTRAN — words to ignore:
also and are assuming at avoid be can check clear cover dan dangerous do drivers driving equipped etc find get if in need no of other our out run s serve service so somewhere sure t the there they thoroughly to under we with without won you your
Input to XTRAN — Regular expressions for HTML tags to ignore:
^H[1-9]$
Output from XTRAN:
adversary,1 aircraft,1 airplanes,1 collisions,1 darkness,1 destination,1 discreet,1 discreetly,1 especially,1 evasive,2 experts,1 fire,1 ground,1 hostile,1 lights,1 limousine,1 limousines,1 maneuvers,1 mountains,1 nocturnal,1 pilots,1 police,1 radar,2 snacks,1 stealth,2 trained,1 transportation,1 vigilant,1 weather,1