XTRAN Example — XTRAN Data Bases
The following example uses an XTRAN rule set comprising 132 non-comment lines of "meta-code" (XTRAN's rules language).
The rules took less than two hours to write and about ½ hour to debug. (That's right, just over two hours total!)
Note that this example is not intended to be a serious data retrieval application; it is to show how using XTRAN data bases in your XTRAN rules makes code and data manipulation both easy and flexible.
For information about XTRAN data
bases, click ![]()
![]() .
.
For an example showing how to use XTRAN
to automate loading of DSV data into an
XTRAN data base, click
![]()
![]() .
.
Using an XTRAN data base to organize and retrieve data
In this example, the XTRAN rules read data as comma-separated values (CSV), and store the data in an XTRAN data base as follows:
| 1st subscript |
2nd subscript |
Cell contents |
|---|---|---|
| <rcdnum> | Record fields, as comma-separated values | |
| <label> | <value> | <rcdnum>s whose field labeled <label> has <value> |
The rules ignore any input line that is empty or starts with a semicolon, and they assume that the first non-comment input line comprises field labels. This is a common way to handle delimiter separated values (DSV).
The rules then repeatedly prompt the user for a field label and corresponding value for which to search, and display the records found, with the search field suppressed.
Since these XTRAN rules read and parse only text, we use a version of XTRAN that parses its own rules language, but not any other language.
NOTE that although this example happens to involve personnel
data, by using different field labels and corresponding data,
these exact same rules can store and retrieve any
kind of data -- for instance, a global symbol cross-reference extracted
from a large software system using XTRAN
code analysis rules ![]()
![]() , to
allow browsing the information
interactively.
, to
allow browsing the information
interactively.
(We also have XTRAN rules
that allow querying any DSV data interactively.)
![]()
![]()
How can such powerful and generalized data storage and retrieval be automated in 2 hours and only 132 lines of XTRAN rules? Because there is so much capability already available as part of XTRAN's rules language. The rules used for this example take advantage of the following functionality provided by that rules language:
- Text file input and output
- Text manipulation
- Text formatting
- Delimited list manipulation
- Environment variable manipulation
- Content-addressable data bases
The input to and output from XTRAN are untouched.
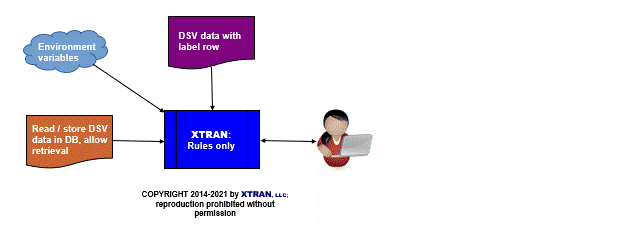
Process Flowchart
Here is a flowchart for this process, in which the elements are color coded:
- BLUE for XTRAN versions (runnable programs)
- ORANGE for XTRAN rules (text files)
- PURPLE for text data files
Input to XTRAN:
; Field labels: last-name,first-name,age,gender ; Data: Cooper,Janice,73,F Dodson,Frank,45,M Dodson,Mary,43,F Jones,William,21,M Smith,Gregory,22,M Smith,Alice,21,F Smith,Lulu,3,F Williams,Mary,63,F
Interactive results (this indicates user
input):
Reading data base...
Enter <fldnam>=<value> or ? for help [done]: ?<ENTER>
<fldnam> must be one of: last-name,first-name,age,gender
Enter <fldnam>=<value> or ? for help [done]: first-name=Mary<ENTER>
last-name = Dodson
age = 43
gender = F
last-name = Williams
age = 63
gender = F
Enter <fldnam>=<value> or ? for help [done]: age=21<ENTER>
last-name = Jones
first-name = William
gender = M
last-name = Smith
first-name = Alice
gender = F
Enter <fldnam>=<value> or ? for help [done]: last-name=Dodson<ENTER>
first-name = Frank
age = 45
gender = M
first-name = Mary
age = 43
gender = F
Enter <fldnam>=<value> or ? for help [done]: age=99<ENTER>
No records qualify.
Enter <fldnam>=<value> or ? for help [done]: gender=F<ENTER>
last-name = Cooper
first-name = Janice
age = 73
last-name = Dodson
first-name = Mary
age = 43
last-name = Smith
first-name = Alice
age = 21
last-name = Smith
first-name = Lulu
age = 3
last-name = Williams
first-name = Mary
age = 63
Enter <fldnam>=<value> or ? for help [done]: <ENTER>