XTRAN Example — Count Words in Text
Menu
- Introduction & strategy
- Common XTRAN input
- Scenario 1 — Ignore uninteresting words
- Scenario 2 — Process only interesting words
Introduction & strategy
Scenario — you want to count word occurrences in text, and you want to either ignore some words or count only specified words.
XTRAN to the rescue!
The following analyses use XTRAN rules comprising 143 non-comment lines of XTRAN's rules language ("meta-code") to count words in text — English prose in this case, but the rules can handle any language (human or computer) — in fact, any text input.
These rules took less than one hour to create and less than ½ hour to debug. (That's right, just over one hour total!)
The results output is alphabetically ordered and in delimiter separated value (DSV) form, suitable for input to a spreadsheet or data base for further analysis, graphing, etc.
The rules force all input to lower case before counting the words, to avoid issues with upper vs. lower case in the text.
The rules allow you to optionally specify, via environment variables, the following features:
- Characters that delimit words, defaulting to
<SPACE> <TAB> , ; . ? ! - The name of a text file containing either (but not both):
- Words to ignore in the counts. Typically these will be
pronouns, connectives, prepositions, etc., whose counts would not be
interesting.
(or) - Words to process in the counts, ignoring all other words.
- Words to ignore in the counts. Typically these will be
pronouns, connectives, prepositions, etc., whose counts would not be
interesting.
- The format of each word count in the output, specified as
a
printf()format spec, which must contain exactly one text string (%s) spec for the word and exactly one integer (%d) spec for the count, in either order, defaulting to%7d,%s
If needed, you can use existing XTRAN
rules ![]()
![]() to summarize the resulting word counts across multiple
documents.
to summarize the resulting word counts across multiple
documents.
We have also adapted these rules to mine HTML Web
pages ![]()
![]() for
keywords.
for
keywords.
How can such powerful and generalized text manipulation be automated in less than 1½ hours and only 143 code lines of XTRAN rules? Because there is so much capability already available as part of XTRAN's rules language. These rules take advantage of the following functionality:
- Text file input and output
- Text manipulation
- Text formatting
- Delimited list manipulation
- Regular expression matching
- Environment variable manipulation
- Content-addressable data bases
- Creating new meta-functions written in meta-code, which we call user meta-functions
The XTRAN rules used for both scenarios are exactly the same. The input to and output from XTRAN are untouched.
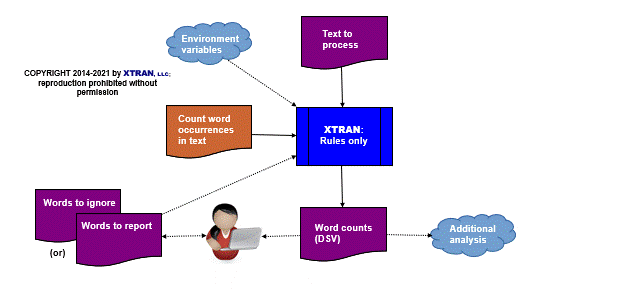
Process Flowchart
Here is a flowchart for this process, in which the elements are color coded:
- BLUE for XTRAN versions (runnable programs)
- ORANGE for XTRAN rules (text files)
- PURPLE for text data files
The process is the same for both scenarios.
Common XTRAN Input
The text input to XTRAN for analysis is the same for both scenarios:
This is some text on which we will do a word count, writing out the results as CSV. The word count will have been filtered according to the contents of a named filter file.
Scenario 1 — Ignore uninteresting words
In this scenario, we tell the XTRAN rules
to ignore a list of insignificant words we provide. We also
specify a format of %07d?%9s for the output lines.
Input to XTRAN — words to ignore:
a do the which and have this will are is to would as of we be on when been some where
(By the way, we used XTRAN rules to format
the list above into columns from its "one item per line" file.)
![]()
![]()
Output from XTRAN:
0000001?according 0000001? contents 0000002? count 0000001? csv 0000001? file 0000001? filter 0000001? filtered 0000001? named 0000001? out 0000001? results 0000001? text 0000002? word 0000001? writing
Scenario 2 — Process only interesting words
In this scenario, we tell the XTRAN rules to
count only a list of specific words we provide. We also
specify a format of %-10s%d for the output lines.
Input to XTRAN — words to count:
contents count csv filter filtered text word
Output from XTRAN:
contents 1 count 2 csv 1 filter 1 filtered 1 text 1 word 2