XTRAN Example — Sum Integer Field in DSV Data
Scenario — you have some delimiter-separated value (DSV) data, and you want to sum one delimited field for each value that occurs in another field.
XTRAN to the rescue!
The following example uses an XTRAN rules file comprising 82 non-comment lines of "meta-code" (XTRAN's rules language) to sum one field across value occurrences in another field in DSV data.
The rules took less than an hour to write and about ¾ hour to debug. (That's right, less than 1¾ hours total!)
This is an example of XTRAN's ability to automate the manipulation of data as well as code.
You specify to the rules, via environment variable values:
- The name of a file name file that names all DSV data files to process, one file name per line
- Which DSV field (1-n) has the values to create sums for
- Which DSV field (1-n) to sum (must be integer in every record)
- (optionally) The DSV delimiting character, defaulting to comma
For instance, given the following DSV data input:
Fred,5 Mary,4 Fred,3 Fred,10 Mary,7
If you specify that the second field is to be summed for occurrences of values in the first field, the output will be
Fred,18 Mary,11
This allows you to, for example, sum occurrences of words in
text ![]()
![]() across
multiple documents, or occurrences of keywords mined from Web
pages
across
multiple documents, or occurrences of keywords mined from Web
pages ![]()
![]() across
an entire site.
across
an entire site.
In fact, we have used these rules to summarize keyword occurrences across this very site, processing about 7,000 occurrences of about 850 keywords.
How can such powerful and generalized data manipulation be automated in less than 1¾ hours and only 82 lines of XTRAN rules? Because there is so much capability already available as part of XTRAN's rules language. These rules take advantage of the following functionality:
- Text file input and output
- Text manipulation
- Text formatting
- Delimited list manipulation
- Regular expression matching
- Environment variable manipulation
- Content-addressable data bases
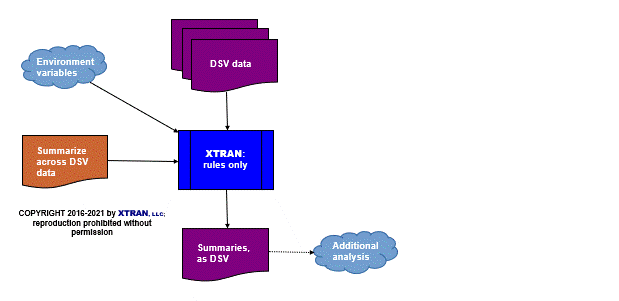
Process Flowchart
Here is a flowchart for this process, in which the elements are color coded:
- BLUE for XTRAN versions (runnable programs)
- ORANGE for XTRAN rules (text files)
- PURPLE for text data files